Learning non-stationary and discontinuous functions using clustering, classification and regression
Principal investigator: Dr. M. Moustapha
Description
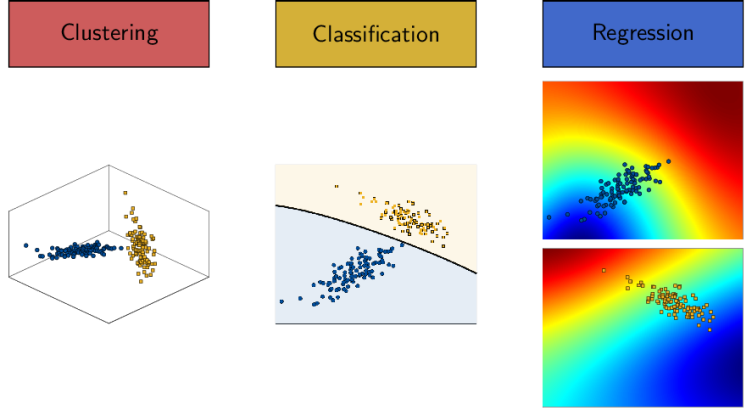
Surrogate models have shown to be essential for the solution of otherwise intractable problems in engineering, where repeated calls to a high-fidelity computational model are required. These inexpensive approximations are typically built by evaluating the original model on a set of carefully selected samples. A crucial aspect of surrogate modelling is the assumption of smoothness and regularity of the model to emulate. This is, however, not met in many engineering problems involving strong localized features or extreme regime variations, e.g., instability patterns or buckling in crashworthiness simulation.
The goal of this project is to construct accurate surrogate models in such cases where traditional approaches fail. To this end, we consider a three-stage approach that combines a sequence of well-known machine learning techniques: clustering using Dirichlet process mixture models, classification using support vector machines and regression using Gaussian process modelling (external pageMoustapha and Sudret, 2023). These three steps allow us to automatically split the input space along the discontinuities or into subdomains of similar behavior. Local regression models are then built in each subdomain and later combined when making predictions. This methodology may also be extended to directly account for the epistemic error in each step of the three-stage approach.
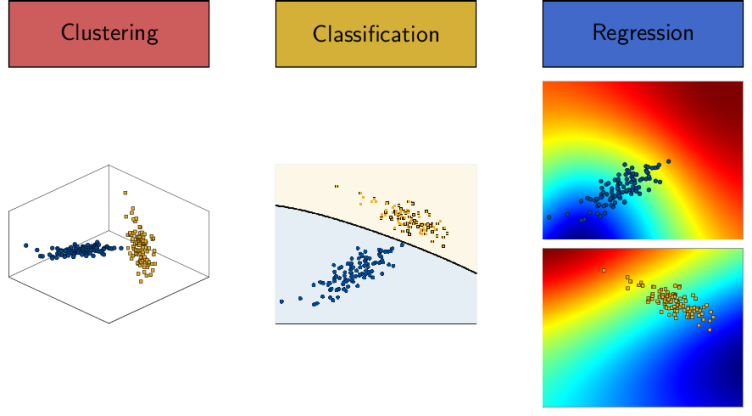
Ersatzmodelle haben sich als unverzichtbar für die Lösung sonst unlösbarer Probleme im Ingenieurwesen erwiesen, bei denen wiederholte Aufrufe eines rechenintensiven Modells erforderlich sind. Diese kostengünstigen Näherungen werden typischerweise durch Auswertung des Originalmodells anhand einer sorgfältig ausgewählten Stichprobe erstellt. Ein entscheidender Aspekt bei der Ersatzmodellierung ist die Annahme von Glattheit und Regularität des zu emulierenden Modells. Dies wird jedoch bei vielen ingenieurtechnischen Problemen nicht erfüllt, die starke lokalisierte Merkmale oder extreme Regimewechsel aufweisen, z.B. Knicken in der Crashsicherheitsimulation.
Das Ziel dieses Projekts ist es, genaue Ersatzmodelle in solchen Fällen zu konstruieren, in denen herkömmliche Ansätze versagen. Zu diesem Zweck betrachten wir einen dreistufigen Ansatz, der eine Folge von bekannten Machine-Learning-Techniken kombiniert: Clustering mit Dirichlet-Prozess-Mischmodellen, Klassifikation mit Support Vector Machines und Regression mit Gauss-Prozess-Modellierung (external pageMoustapha und Sudret, 2023). Diese drei Schritte ermöglichen es uns, den Eingaberaum entlang von Diskontinuitäten automatisch aufzuteilen oder in Teilbereiche mit ähnlichem Verhalten zu unterteilen. Lokale Regressionsmodelle werden dann in jedem Teilbereich erstellt und später bei der Vorhersage kombiniert. Diese Methodik kann auch erweitert werden, um die epistemischen Unsicherheiten in jedem Schritt des dreistufigen Ansatzes direkt zu berücksichtigen.